

Standby, or Stand Firm? (Part 2)
That they are endowed with certain unalienable rights, That among these are life, liberty, and the purchase of firm power.


In a historic event for our great nation, delegates from the thirteen states convened in the city of Philadelphia, Pennsylvania with one mission: they had a new vision for the future of their union. They wanted new governance, and they wanted it now. The electric bills were too bloody high.
This was the scene two weeks ago as a bipartisan bloc of PJM-state governors came together to take skyrocketing capacity costs and fumbled process into their own hands. All of this is unfolding as PJM’s CEO Manu Asthana prepares to abdicate at year’s end.
But beneath those political headlines, an in-the-weeds fight has been playing out in the PJM Interconnection, one that decides whether AI gets built here, at scale, and on time: what kind of power service data centers receive, how much risk they shoulder, and how quickly they connect.
The Roadmap for This Edition
Today is Part 2 of Standby, or Stand Firm?, a series on AI data centers, flexible load, and PJM’s plan for dealing with it: Non-Capacity-Backed Load (NCBL). In Part 1, I explained PJM’s concept for NCBL, a “standby” lane for large loads that become the first to curtail when the grid is stressed. I also highlighted some flaws of NCBL that triggered the swift backlash from all sides.
That’s where today’s issue picks up. First, I’ll give an update on recent changes to NCBL and noteworthy counter-proposals from stakeholders. After that, today’s edition will serve as a primer dedicated to all things “flexible data center” and “flexible load.” I’ll unpack key terminology, including service class (what you’ve contracted for) versus market mechanisms (how you behave). We’ll also look at how AI data centers actually flex, from the campus level down to the GPU core. To top it off, we’ll finally learn the lore behind the flexible data center: its origins and the key scientific result that’s been all the rage this year.
What’s New With NCBL?
Mandatory NCBL is no more
They proposed. Hyperscalers said, “No.”
PJM has walked back the mandatory component of its NCBL construct, unveiling changes in its meeting last Wednesday, October 1st. In Part 1, we witnessed that the third rail of the NCBL proposal, the thing that turned so many heads, was the mandatory backstop. The idea of forcing standby status—allocating NCBL whether you opted in or not—was a non-starter for data centers that live and die by uptime and service commitments to their customers. This latest announcement has its jargon, some of which I demystify in the section “Service Classes vs. Market Mechanisms” that follows. For now, I’ll give a quick rundown.
In PJM’s newest slide deck, flexibility takes the form of pre-existing, voluntary tools:
Demand response (DR): paid, event-based reductions during system stress.
Price-responsive demand (PRD): a pre-filed, price-indexed reduction plan, modified by PJM to use the energy-market offer price.
PJM also outlines process changes:
Load Forecasting: add a state-commission review of large-load adjustments before the forecast is finalized; require submitters to disclose duplicative requests.
Expedited Interconnection: create a 10-month Expedited Interconnection Track for “sponsored generation” (e.g., supported by a state commission) with strict eligibility (e.g., >500 MW) and project responsibility for paying 100% of needed network upgrades.
Longer-term procurement: open a discussion for alternatives to the region’s traditional reliability backstop, which solicits capacity for a single delivery year at a time; this would allow procurement of capacity for longer periods.
In short, PJM is stepping away from a blunt, mandatory standby class and toward a menu of voluntary flex behaviors. It also floats a variety of process changes, all aimed at improving long-term resource adequacy in the region.
Hyperscalers become generators…of policy
Industry stakeholders, for their part, have mounted an unusually proactive response to the heavy-handed NCBL since its bombshell release in August. In a scarcely seen, coordinated intervention in regional market design, hyperscalers including Amazon, Google, and Microsoft have proposed a complementary package of reforms consisting of three pillars:
Improving Load Forecasting: count only loads with verifiable commitments; reduce counting of duplicates; implement “reality checks” informed by supply chain conditions, expert studies, etc.
Demand-Side Actions: enable limited-hours DR; establish an emergency step to run on-site backup generation before any manual load-shed; offer a purely voluntary curtailment option.
Procurement of Multi-Year Capacity: if the region remains short, run a multi-year capacity procurement to incentivize new supply. Generators bid for contracts lasting 1-7 years, though shorter terms clear first. The price is set at PJM’s standard reference point (the maximum on its capacity demand curve) and gets locked in for the life of each contract. This temporary program sunsets after the 2031/32 delivery year.
PJM vs. Hyperscalers: Where do their latest visions agree?
Voluntary vs. mandatory: Agree.
PJM scrapped the compulsory allocation of NCBL.Load forecasting: Agree.
PJM’s newly proposed due diligence for load-forecasting (state-level review, duplicate-request screens) is in spirit with hyperscalers’ requests that PJM first ensure estimates of future need are credible.Demand-side mechanics: Specifics TBD; room to agree.
PJM’s pathway is to use some combination of existing DR and a modified PRD mechanism. Hyperscalers go further, crafting a limited-hours DR product (24–100 hours/year).Emergency playbook: TBD; room to agree.
PJM has only vaguely flagged a review of manual load-shed allocation, to be conducted at a later date. Hyperscalers ask for a specific rule to dispatch on-site backup generation immediately before manual load-shed. This request may raise environmental/permitting wrinkles.Generator interconnection: TBD; room to agree.
PJM has proposed a 10-month Expedited Interconnection Track for sponsored generation. The latest coalition deck says nothing on this, but hyperscalers have historically supported generation projects that are colocated or paired with load.Longer-term capacity procurement: TBD; room to agree.
PJM mentions the idea of longer-term reliability purchases. Hyperscalers lay out a concrete process for procuring multi-year resources beyond PJM’s usual capacity auction, which procures capacity for just one year.
What’s the upshot? Both sides are now gesturing toward voluntary flexibility executed through DR-like mechanisms. What remains is to decide contractual and operational details: explicit curtailment caps, advance notice, published priority order, compensation for curtailment, and an emergency sequence—including whether and when to use backup generation. On some of these fronts, industry stakeholders have offered their version of the specifics.
Furthermore, both parties are looking at future years, with recommendations to reinterrogate potentially inflated load forecasts and to allow contracts for longer-term capacity. The industry slide deck’s recommendations for improving the accuracy of future load forecasts are sensible—and I would not be surprised to see PJM’s official numbers decrement as a result of implementing these actions—but if you ask me, it’s largely wishful thinking on the part of the industry coalition. Even if estimates come down, it’s fanciful to imagine they’ll do so by enough to dig us out of the present situation. We’re fundamentally in a state of resource inadequacy.
Update 10/8/25: The above section was revised for accuracy.
Certain unalienable rights
Hyperscalers gave us a reminder that state governors aren’t the only ones staging an intervention in PJM. The giants of the AI industrial base, who have seldom seen regional grid policy as part of their job, are architecting their own vision for regulating flexible load. In doing so, hyperscalers are drawing a line: the freedom to choose firm over flexible is, for them, a certain unalienable right.
For my part, I don’t think that flexibility ought to be verboten. Rather, it can be a fantastic opportunity. I do think that forced, open-ended flexibility poses a massive risk. If exposure to that risk is unbounded, you can’t plan AI workloads. If you can’t plan, you don’t build. That’s the decision calculus.
Just CHILL: The Response to Large Loads Out West
Let’s take a brief excursion inland. The same story of large loads has transpired across the country, albeit more cool-headedly. Consider the Southwest Power Pool (SPP), whose board approved a High-Impact Large Load (HILL) policy on September 16th, establishing a 90-day study-and-approval path for large loads paired with new or planned generation. This is an excellently generative idea, literally, since it enlists loads to help solve the supply shortage. A companion idea—wryly named Conditional HILL (CHILL)—would provide expedited, non-firm access in exchange for defined curtailment rights. That makes it something of a more mature cousin to NCBL, but CHILL has been deferred to a later tariff revision. PJM is moving in the right direction, but the execution has been decidedly rougher than out west.

Fundamentals of flexibility:
service classes vs. market mechanisms
Many readers will know the buzzwords. Demand response. Demand flexibility. Demand-side management. Flexible data centers. Flexible load. Same thing…right? The ontology of flexible load involves two animals: (1) service classes and (2) market mechanisms.
Firm service class (a high-priority contract).
This is the default class. You energize when ready and—short of extraordinary conditions—remain served. You have top curtailment priority; all others curtail before you. No pre-commitment to reduce; any turn-down in power is at your discretion.Flexible service class (a lower-priority contract).
This is a distinct class that has gone by various names in various jurisdictions (e.g., interruptible/curtailable/non-firm service). You opt into a lower-priority lane in exchange for something you value, often earlier energization and sometimes lower charges. The contract has clear terms:caps on total hours (or total energy) curtailed
notice windows (e.g., day-ahead advisory, plus same-day call)
published priority of each customer in the curtailment order
basic verification so that performance is auditable.
PJM’s proposed Non-Capacity-Backed Load (NCBL) is best understood as an instance of flexible service.
Market mechanisms (DR, PRD).
These are behaviors theoretically available to a customer in any class.Demand response (DR): event-based reductions that you perform for compensation when the operator signals so.
Price-responsive demand (PRD): a pre-filed, rules-based plan that automatically reduces your load in real time as the market price crosses certain thresholds.
Two clarifications for good measure
Participating in DR/PRD does not change your service class. A firm customer can do DR/PRD and remain firm.
In a flexible contract, your system operator may use DR/PRD-style tools to implement your obligations, but that does not make DR/PRD the service class.
In short: service class sets your curtailment priority while DR/PRD market mechanisms are agreed ways to behave during special events.
How to Flex Your Data Center
In practice, the tools that sophisticated customers use to execute DR and PRD behaviors aren’t just light switches; their power draw can be tuned smoothly. Could AI factories do the same? As I wrote in Part 1, ventures like Verrus AI and Emerald AI’s orchestration at an Oracle data center in Phoenix show that software can, in real time,
modulate the total load of a site
delegate jobs among sites (spatial shifting)
defer jobs to later (temporal shifting).
Flexible to the core: GPU-level power controls
But I’ve spoken to a few engineers building something neater: fine-grained GPU controls that fit naturally into DR/PRD. Using dynamic voltage and frequency scaling (DVFS) to adjust the clock frequencies of GPU cores across multiple discrete setpoints, even an individual chip can track a price signal or instruction quasi-continuously. Practically, that means you don’t need to halt jobs when the grid tightens; you just run the entire fleet less intensively.
In other words, operating your site at 80% can be achieved in multiple ways:
four-fifths of GPUs at full tilt with one-fifth idle
the entire fleet running at a moderately reduced clock frequency (e.g., ~90%) that corresponds to an 80% power draw1
something in between.
Furthermore, the more levels and axes along which we can adjust computing load (temporal/spatial, campus/rack/chip, etc.), the more sophisticated the solutions available to us, including highly intelligent, reinforcement-learning-based workload management that can conduct a country of data centers in a seamless symphony.
This is a dynamic field evolving every day, with low-hanging fruit to be picked. If you’re a reinforcement learning engineer or an operations researcher, this is one of the most fascinating ways you could help improve the efficiency, reliability, and competitiveness of American AI and the grid. Every innovation can be deployed to AI factories at massive scale.
Flexible Data Centers: The Lore and The Seminal Whitepaper
“We’ve never planned loads this way,” says Norris, but “it’s effectively impossible to see how some of these load forecasts can be met with purely physical infrastructure building.”
In February 2025, a team at Duke University’s Nicholas Institute—Tyler Norris, Danny Profeta, Esteban Patiño-Echeverri, and Cowie-Haskell—gave a crisp name to a practical idea: curtailment-enabled headroom, herein abbreviated CEH. It’s presented in their now-landmark paper “Rethinking Load Growth,” and the claim is straightforward: if large loads pre-commit to brief, bounded curtailments in narrow windows when the system is tight, the grid can absorb much more demand without waiting years2 for new build-out. Their first-order national estimate:
76 GW for ~0.25% annual curtailment
98 GW for ~0.5% annual curtailment
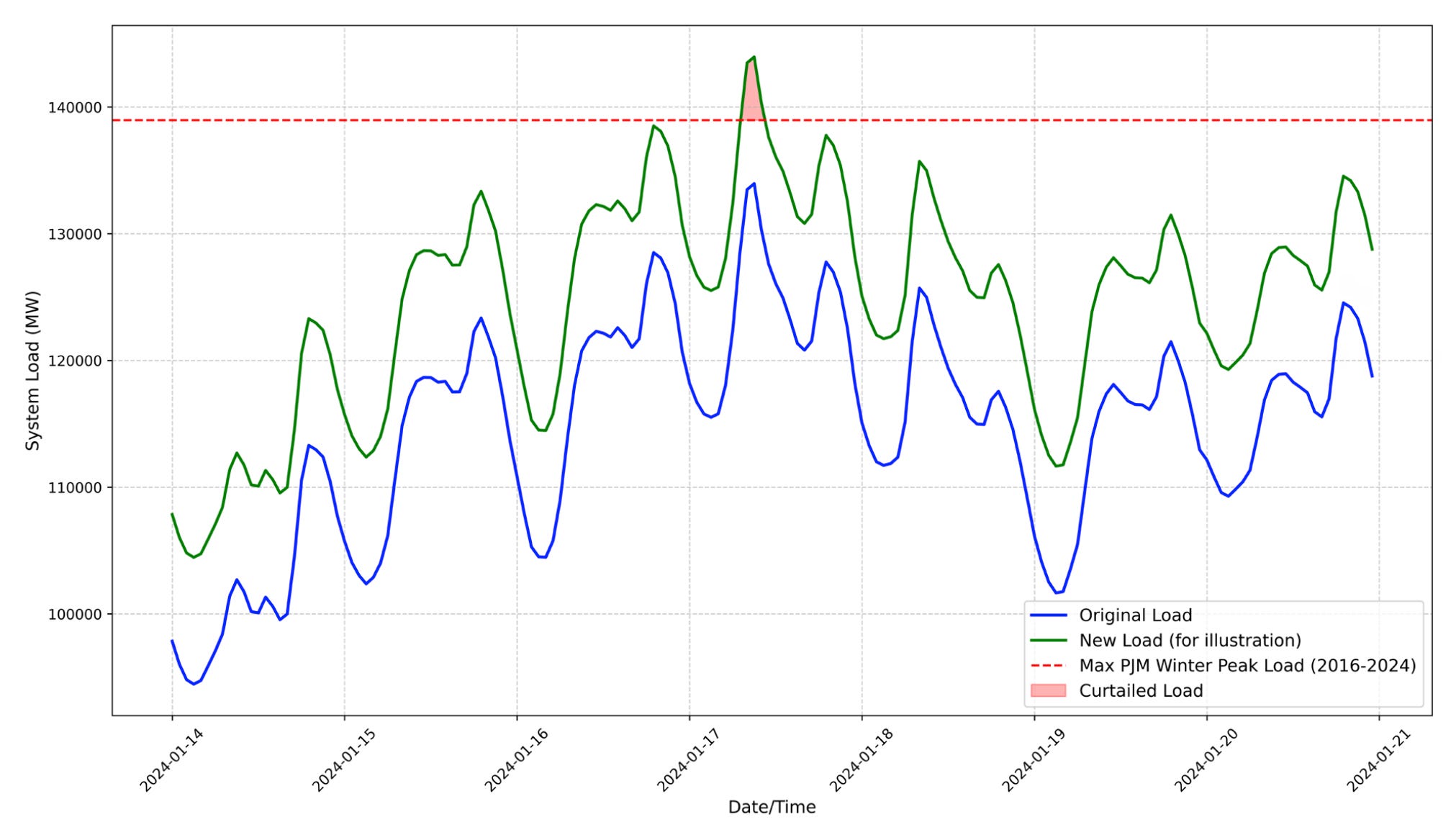
What do “narrow windows” mean? Grid stress is concentrated in a few hours of the year—late-afternoon peaks on the hottest days, frigid morning ramps, the occasional unplanned outage window—when load spikes against the capacity ceiling. CEH supposes that large loads hold back just during those spikes, not across the whole year.
For calibration: 1 year = 8,760 hours.
0.25% ≈ 22 hours/year.
0.5% ≈ 44 hours/year.
For context, many government and industry studies have forecasted U.S. data-center-driven demand growth by 2030 to be in the neighborhood of 80-100 GW. If this is the case, the implications from Norris et al. are huge. Even a small exercise in CEH could be enough to cover 100% of load growth—zero new generation needed.
PJM, Meet CEH.
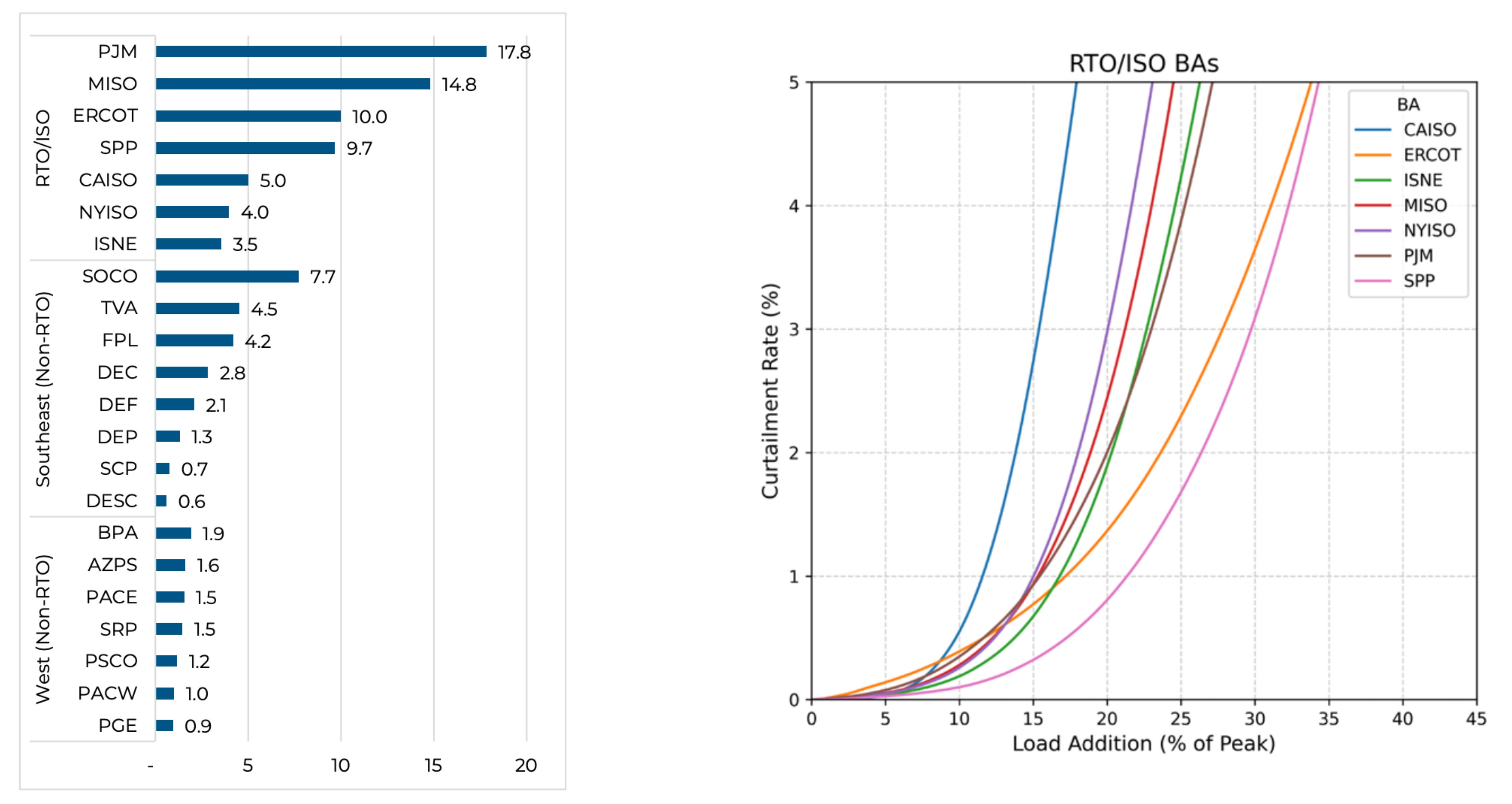
How well does CEH scale in PJM? The region now projects roughly 32 GW of additional coincident peak by 2030, with about 30 GW attributed to data centers.
Against that backdrop, Norris et al. estimate that PJM would free up 17.8 GW under the ~0.5% curtailment scenario: that means we could accommodate 56% of incremental load growth if customers coordinate and curtail.
CEH: ~Necessary But Not Sufficient
CEH is a concept with the potential to circumvent America’s resource inadequacy for years to come if we have the right service classes, market mechanisms, and hardware in place. Of course, that’s turning out to be no small “if.”
First-order analysis is a first step
The Duke paper is intentionally first-order: it aggregates load and aggregates supply. In practice, America’s generators and batteries do not sit in one big lump, and neither does load. Delivery is fine-grained, bottlenecked by particular buses and substations. In other words, a surplus three states away doesn’t help if your local breaker is already at its limit. Norris et al. are upfront about this limitation, and they encourage further investigation.
We need hard numbers and hardware
There remain two practical gaps to planting these flexible loads around America:
Siting intelligence.
Developers lack visibility into local constraints: substation hosting capacity, feeder headroom, queue interactions at transmission voltage, and more. At the distribution level (low voltage), some maps of hosting capacity exist. What’s missing is a PJM or nationwide analogue at the transmission level (high voltage). Builders need to see substation headroom—posted publicly and updated quarterly, for instance—with standard options and timelines for upgrades. That lets builders land where the grid actually has room.Physical equipment.
At nodes of the grid known to be at capacity, the limiting pieces can be prosaic: power transformers and other high-voltage gear. Wait times for distribution transformers have stretched into the two-year range, and large power transformers are globally supply-constrained. Under these conditions, solving power bottlenecks calls for targeted substation expansion and clear cost-sharing. Notably, that could include Contributions in Aid of Construction (CIAC), which are direct, customer-funded upgrades for work that can be imputed to a specific load.
Curtailment-enabled headroom and the findings of Norris et al. were a watershed result. Flexible power as a ramp to a permanent regime will be all but necessary if we are to maximize the medium-term realization of American data centers, but it certainly won’t be sufficient. All paths forward will require us to move both data and metal.
Next Time
Who thought that grid policy in PJM would be like watching a period drama? After all, not every commodity market has governors descending on Philadelphia to declare the causes which impel them to the separation.
By popular demand—and by the sheer frenzy of activity in PJM—the Standby, or Stand Firm? series will continue with Part 3 on a simple premise:
“We want to build AI compute in America, and we want it fast.
What’s the optimal flexible load policy for the job?”
This will give us a grading rubric for “flexible load done right.” And depending on how fast negotiations over NCBL wrap up, we might be able to give PJM a report card.
Update 10/10/25: Supplemental derivation added.
Dynamic switching power for a GPU core scales with capacitance, voltage squared, and frequency. It turns out that voltage and frequency are linked. Reducing frequency allows for a reduction in operating voltage:
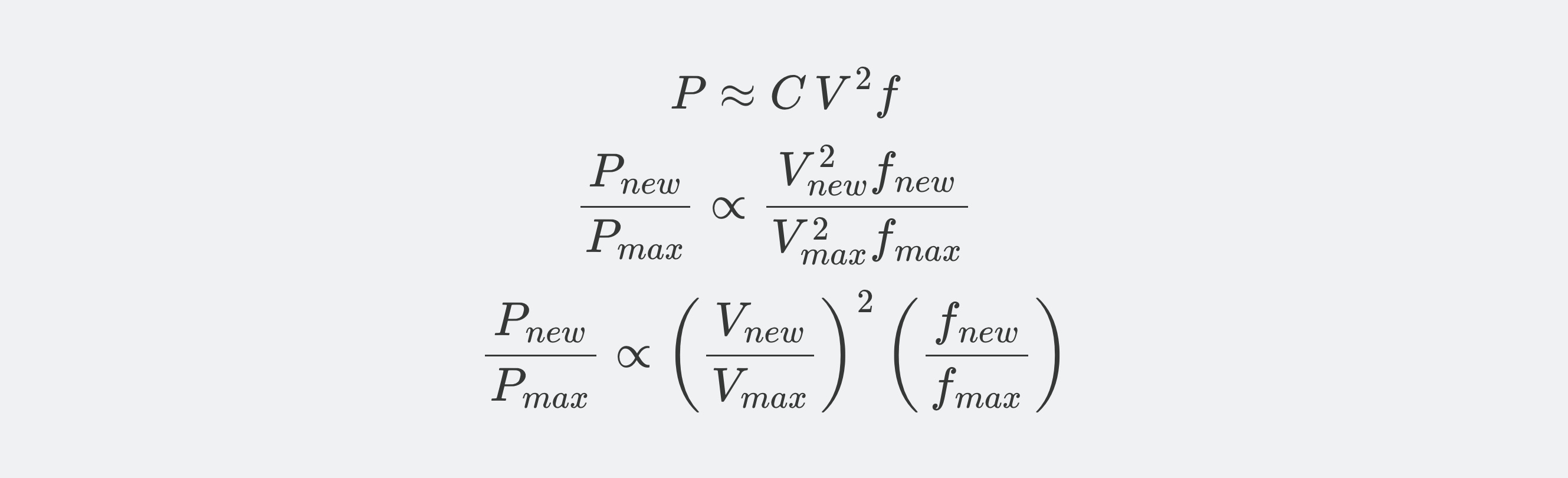
The exact relationship (i.e., the curve of V vs. f) is complex and varies by chip, but we can use a realistic estimate to illustrate the principle. Assume a 10% reduction in clock frequency (i.e., new frequency is 90% of old frequency). Realistically, this might allow for a 5% reduction in voltage (i.e., new voltage is 95% of old voltage). Plugging these values in, we can calculate the new power level:
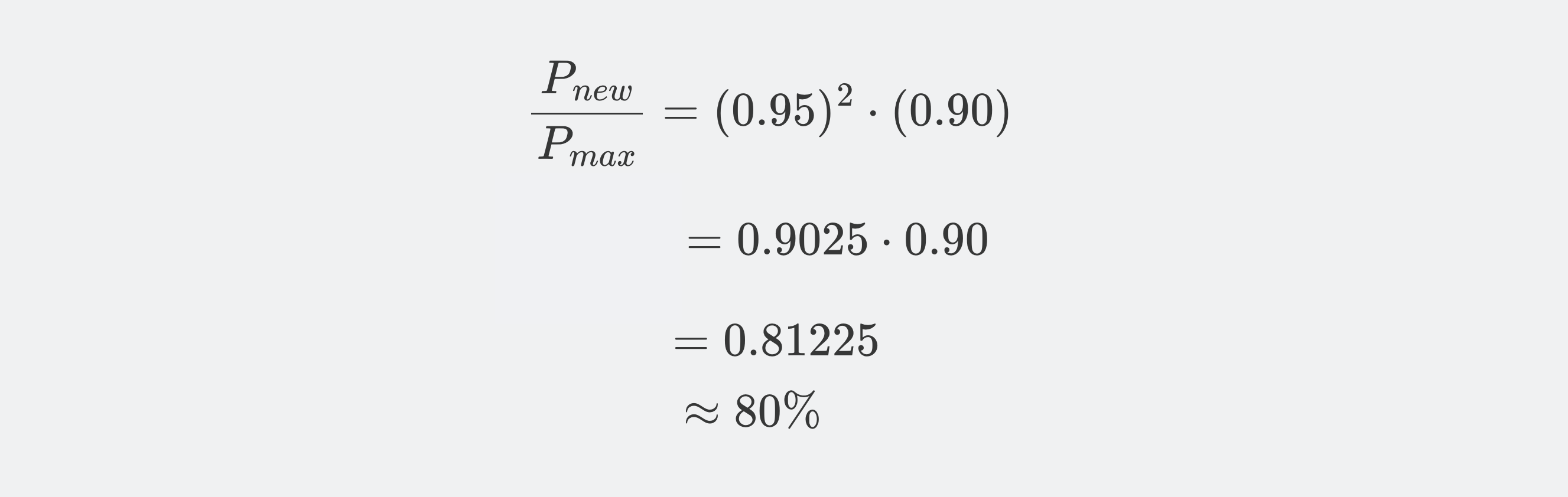
To summarize, setting clock frequency (i.e., computing speed) to 90% of its maximum value has the convenient side effect of lowering the transistor voltage required. Empirically, a realistic value for this new voltage would be around 95% of the maximum voltage. The result is a power use of approximately 80% the maximum power of the chip.
Time to Power → Realized Utilization: A Better Heuristic
If time to power is an unfamiliar concept, I’d recommend first reading Standby, or Stand Firm? (Part 1) or my colleague Dean Ball’s “Out of Thin Air.” In Part 1, I argued that time to power dominates the go/no-go for data center developers. But if a flexible campus energizes quickly and then spends half its time curtailed, you’ve simply swapped one form of lost business revenue for another. In the extreme, sustained curtailment can jeopardize availability commitments, such as the Service-Level Agreements (SLAs) and uptime guarantees signed between compute providers and clients. Moreover—aside from the opportunity cost of lost revenue—your most expensive asset (read: GPUs) will sit unutilized. At first order, it’s true that time to power dominates data center deal-making right now. Accepting a second order of nuance, we can imagine data centers optimizing over two factors:
Time to power: How soon your site energizes.
Utilization: How fully your site is computing at a given instant.
Call this heuristic over two factors “realized utilization.” The second part, “utilization,” can be expressed as a percentage and conveys how close to maximum potential output you are running. Note that this is different from the concept of “uptime,” because whereas uptime describes the fraction of time that a facility spends in the operational state of the up/down binary, utilization describes the fraction of maximum potential computing achieved at a given instant. The first part of the heuristic, “realized,” conveys a preference to capture revenue and machine learning advancements over more of the calendar.
Taken together, realized utilization is a simple way to ask, “For a given curtailment scheme, in exchange for a given acceleration in energization, how much compute will you deliver over the time(s) that matter to you?”
It’s Intuitive
One can see how these two factors trade off. Suppose you have an offer to cut months off your time to power in exchange for flexible service that shaves a bit off your utilization (e.g., 0.1%). Assuming you would have run at 99.9% utilization on a firm service (an oversimplification for illustration), that means 99.8% utilization instead. That could be a great deal. If, however, your utilization would need to decrement further—down to 95.0%, let’s say—it might still be a worthy tradeoff, but it’s intuitive that there comes a breakeven point, where the sacrifice in utilization hurts as much as the expediency in energization helps.
It’s Non-Rigorous
This remains a simplification of the real optimization problem(s). Different builders weight the terms differently. An America-loving frontier AI lab may rationally accept lower near-term utilization to start experiments sooner. A steady compute vendor may prefer to wait for firm service to guarantee high, predictable delivery.
Much as hyperscalers aren’t all optimizing one quantity, the upshot of the flexible load debate isn’t black or white: whether flexibility is “good or bad.” We ought not to forget that flexibility is a provisional regime for the grid’s growing pains, giving data centers a path forward when the alternative is that they not get built at all. If the rules of the flexible regime are clear enough for developers to price the risk, some rationally trade a sliver of utilization for a significant reduction in time to power. If uncertainty plagues the process, they understandably won’t—and maybe they shouldn’t.
There might be additional benefits to Data Center operators from adjusting chip clocking. Over-clocking a GPU is generally thought to decrease lifetime. For example: https://techreviewadvisor.com/how-overclocking-affects-your-gpus-lifespan/
Oh hey, a fellow traveler in AI-energy policy!